


您的當(dāng)前位置:首頁 > 常見問題
多科回收丨關(guān)于減輕服務(wù)器負(fù)載
去年發(fā)現(xiàn)我們的字體服務(wù)出人意料的高負(fù)載,尤其是晚上沒什么流量的時候。幸運(yùn)的是,我們發(fā)現(xiàn)了這一問題的根本原因,并大幅提升了字體服務(wù)的性能和系統(tǒng)整體的穩(wěn)定性。
用火焰圖調(diào)試
我一個同事從 Netflix 公司的 Brendan Gregg 那里發(fā)現(xiàn)并部署了一個小巧的火焰圖工具。這個工具可以把多個性能檢測工具的數(shù)據(jù)結(jié)合起來,生成一張本地方法和 JVM 方法資源使用情況的圖象。圖里每一個矩形都代表一個棧幀,矩形的寬度代表資源的使用情況,如 CPU 時間,y 軸代表調(diào)用棧。你可以簡單地通過找出比較寬的矩形來定位出問題所在。這個工具對于調(diào)試字體服務(wù)的性能是非常寶貴的。
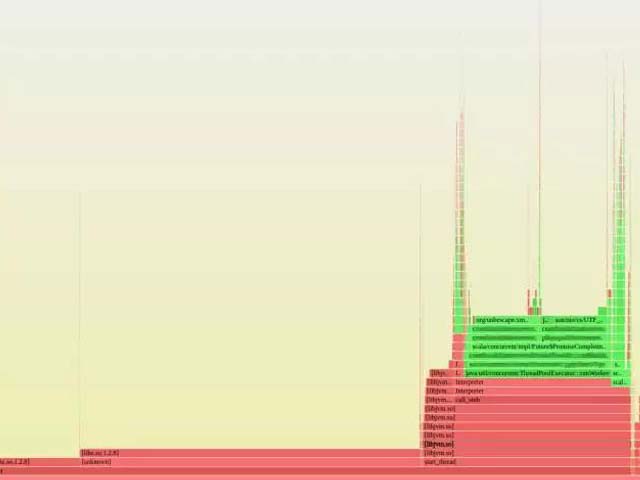
我們收集了幾張字體服務(wù)高負(fù)載狀態(tài)下的火焰圖。下面展示了其中一張,圖里有一處 JVM 部分幾乎到頂。我們很快注意到這些圖的規(guī)律。絕大部分時間都是消耗在 libz.so(用于 gzip 壓縮和解壓)上,而 JVM 里的絕大部分時間都是消耗在 XML 轉(zhuǎn)義和 UTF-8 編碼上。
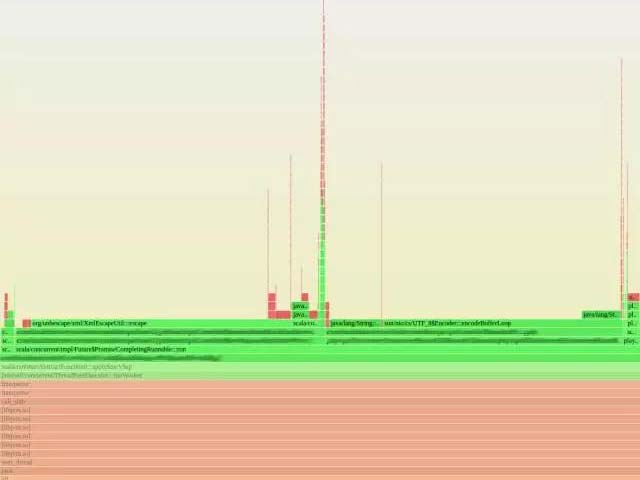
為什么這么慢
首先,介紹一點(diǎn)關(guān)于我們字體服務(wù)如何工作的背景。我們將字體數(shù)據(jù)保存在 Amazon S3 容器中,每一種字體的每一 unicode 編碼范圍(unicode range)是一個獨(dú)立的對象。其他服務(wù)會為字體體系、一系列 unicode 編碼范圍(unicode range)或者用戶來請求字體數(shù)據(jù)。字體服務(wù)會下載用戶請求的字體體系中特定 unicode 編碼范圍(unicode range)的數(shù)據(jù),并返回包含這所有數(shù)據(jù)的 XML。
這一功能非常簡單,并沒有什么明顯密集計(jì)算的東西。然而,我們遇到了高負(fù)載。我們在火焰圖的幫助下發(fā)現(xiàn) libz、XML 轉(zhuǎn)義和 UTF8 編碼占用了 CPU 大量資源。但是為什么我們花了這么多時間在編碼和壓縮上呢?記得我剛才說的,晚上負(fù)載最高嗎?我們的晚上(美國山區(qū)標(biāo)準(zhǔn)時)在亞洲是白天。每當(dāng)晚上我們本地沒什么流量的時候,大量其他地區(qū)的用戶正在用亞洲語言的 unicode 編碼范圍(unicode range),比如中文、日語和韓語。事實(shí)上,相比起來這些類別的字體數(shù)據(jù)是非常龐大的。這些數(shù)據(jù)通過 gzip 解壓、UTF-8 解碼然后 XML 轉(zhuǎn)義、UTF-8 編碼最后 gzip 壓縮。對于體積很小的基本拉丁文類別,這一過程沒什么。然而,CJK 類別比基本拉丁文類別大了兩個數(shù)量級(1MB 對比 60KB)。對于這些體積大的字體類別,這所有的轉(zhuǎn)換都使得 CPU 吃不消。Gzip 壓縮和解壓相對很耗資源,XML 轉(zhuǎn)義也沒有那么快。
怎樣加速
字體服務(wù)響應(yīng)的內(nèi)容本質(zhì)上只是來自 S3 的原始數(shù)據(jù)。字體服務(wù)的確做了其他重要的工作,比如權(quán)限驗(yàn)證,查找字體關(guān)鍵字。但是沒有理由必須讓字體服務(wù)從 S3 轉(zhuǎn)發(fā)字體數(shù)據(jù)。我們的解決方案非常簡單粗暴,直接返回一系列包含字體數(shù)據(jù)的 S3 對象的鏈接,而不是通過字體服務(wù)下載然后重新編碼字體數(shù)據(jù)。
這一修改幾乎將字體服務(wù)器的負(fù)載降為 0(見圖1)。客戶端服務(wù)器也察覺不到任何影響。盡管我們第一次嘗試非常成功,但我也應(yīng)該記住,我們部署的同時增加了功能發(fā)布控制,它可以讓我們在 100% 啟用前,先啟用一定比例的請求來測試它能夠正常工作。
結(jié)論
通過對生產(chǎn)環(huán)境服務(wù)器的監(jiān)控,我們能夠定位并刪除服務(wù)器上沒必要的功能。下面是我們這次經(jīng)歷中幾個關(guān)鍵的步驟
用火焰圖等性能檢測工具定位那些霸占 CPU 的功能方法。
壓縮和其他編碼也會非常耗資源。
如果客戶端能夠直接獲取到數(shù)據(jù),那么直接發(fā)給它一個連接而非轉(zhuǎn)發(fā)數(shù)據(jù)會提升整體的性能。(聲明:這并不是靈丹妙藥,有些情況下會對客戶端性能造成損失,因?yàn)樗仨氁龆握埱螅?br />
去年發(fā)現(xiàn)我們的字體服務(wù)出人意料的高負(fù)載,尤其是晚上沒什么流量的時候。幸運(yùn)的是,我們發(fā)現(xiàn)了這一問題的根本原因,并大幅提升了字體服務(wù)的性能和系統(tǒng)整體的穩(wěn)定性。
用火焰圖調(diào)試
我一個同事從 Netflix 公司的 Brendan Gregg 那里發(fā)現(xiàn)并部署了一個小巧的火焰圖工具。這個工具可以把多個性能檢測工具的數(shù)據(jù)結(jié)合起來,生成一張本地方法和 JVM 方法資源使用情況的圖象。圖里每一個矩形都代表一個棧幀,矩形的寬度代表資源的使用情況,如 CPU 時間,y 軸代表調(diào)用棧。你可以簡單地通過找出比較寬的矩形來定位出問題所在。這個工具對于調(diào)試字體服務(wù)的性能是非常寶貴的。
我們收集了幾張字體服務(wù)高負(fù)載狀態(tài)下的火焰圖。下面展示了其中一張,圖里有一處 JVM 部分幾乎到頂。我們很快注意到這些圖的規(guī)律。絕大部分時間都是消耗在 libz.so(用于 gzip 壓縮和解壓)上,而 JVM 里的絕大部分時間都是消耗在 XML 轉(zhuǎn)義和 UTF-8 編碼上。
為什么這么慢
首先,介紹一點(diǎn)關(guān)于我們字體服務(wù)如何工作的背景。我們將字體數(shù)據(jù)保存在 Amazon S3 容器中,每一種字體的每一 unicode 編碼范圍(unicode range)是一個獨(dú)立的對象。其他服務(wù)會為字體體系、一系列 unicode 編碼范圍(unicode range)或者用戶來請求字體數(shù)據(jù)。字體服務(wù)會下載用戶請求的字體體系中特定 unicode 編碼范圍(unicode range)的數(shù)據(jù),并返回包含這所有數(shù)據(jù)的 XML。
這一功能非常簡單,并沒有什么明顯密集計(jì)算的東西。然而,我們遇到了高負(fù)載。我們在火焰圖的幫助下發(fā)現(xiàn) libz、XML 轉(zhuǎn)義和 UTF8 編碼占用了 CPU 大量資源。但是為什么我們花了這么多時間在編碼和壓縮上呢?記得我剛才說的,晚上負(fù)載最高嗎?我們的晚上(美國山區(qū)標(biāo)準(zhǔn)時)在亞洲是白天。每當(dāng)晚上我們本地沒什么流量的時候,大量其他地區(qū)的用戶正在用亞洲語言的 unicode 編碼范圍(unicode range),比如中文、日語和韓語。事實(shí)上,相比起來這些類別的字體數(shù)據(jù)是非常龐大的。這些數(shù)據(jù)通過 gzip 解壓、UTF-8 解碼然后 XML 轉(zhuǎn)義、UTF-8 編碼最后 gzip 壓縮。對于體積很小的基本拉丁文類別,這一過程沒什么。然而,CJK 類別比基本拉丁文類別大了兩個數(shù)量級(1MB 對比 60KB)。對于這些體積大的字體類別,這所有的轉(zhuǎn)換都使得 CPU 吃不消。Gzip 壓縮和解壓相對很耗資源,XML 轉(zhuǎn)義也沒有那么快。
怎樣加速
字體服務(wù)響應(yīng)的內(nèi)容本質(zhì)上只是來自 S3 的原始數(shù)據(jù)。字體服務(wù)的確做了其他重要的工作,比如權(quán)限驗(yàn)證,查找字體關(guān)鍵字。但是沒有理由必須讓字體服務(wù)從 S3 轉(zhuǎn)發(fā)字體數(shù)據(jù)。我們的解決方案非常簡單粗暴,直接返回一系列包含字體數(shù)據(jù)的 S3 對象的鏈接,而不是通過字體服務(wù)下載然后重新編碼字體數(shù)據(jù)。
這一修改幾乎將字體服務(wù)器的負(fù)載降為 0(見圖1)。客戶端服務(wù)器也察覺不到任何影響。盡管我們第一次嘗試非常成功,但我也應(yīng)該記住,我們部署的同時增加了功能發(fā)布控制,它可以讓我們在 100% 啟用前,先啟用一定比例的請求來測試它能夠正常工作。
結(jié)論
通過對生產(chǎn)環(huán)境服務(wù)器的監(jiān)控,我們能夠定位并刪除服務(wù)器上沒必要的功能。下面是我們這次經(jīng)歷中幾個關(guān)鍵的步驟
用火焰圖等性能檢測工具定位那些霸占 CPU 的功能方法。
壓縮和其他編碼也會非常耗資源。
如果客戶端能夠直接獲取到數(shù)據(jù),那么直接發(fā)給它一個連接而非轉(zhuǎn)發(fā)數(shù)據(jù)會提升整體的性能。(聲明:這并不是靈丹妙藥,有些情況下會對客戶端性能造成損失,因?yàn)樗仨氁龆握埱螅?br />



















